

Un artículo de Tomás Mayoral
Una de las primeras veces que utilicé ChatGPT (versión 3,5, la gratuita) le hice varias preguntas sobre las fuentes que había utilizado este modelo de Inteligencia Artificial generativa en su entrenamiento. Fue antes de saber las tropelías que conté con detalle en la primera entrada de este blog con respecto al uso indiscriminado de contenido con copyright durante ese entrenamiento. A pesar de que el Washington Post ya había levantado la liebre de este tema, cuando pregunté al chatbot de OpenAI aún no había habido una respuesta formal de la News/Media Alliance. Dentro de la lógica corrección política de las respuestas, ChatGPT no se cortó un pelo y fue muy concreta y precisa sobre esas fuentes, ofreciendo datos que suponían, como se vería después, cierto compromiso. Por ejemplo, se refirió a contenido que, solo con verlo, dejaba ya un intenso aroma de estar bajo protección de derechos de autor: libros, tesis doctorales, blogs, etc. También aludió en tercer lugar de la lista, nada menos, a material diverso de medios de comunicación. En ese momento me pareció perfectamente normal esa “sinceridad”. (En el primera pantallazo, más adelante, se puede ver la respuesta original)
Sin embargo, unas semanas después, cuando estaba recopilando información para la aludida primera entrada de este blog, pensé que sería interesante volver a hacerle exactamente la misma pregunta. Me quedé de piedra cuando la respuesta fue mucho menos concreta en cuanto a las fuentes que la anterior. Además, la remató con un “No tengo información específica sobre las fuentes exactas o una lista detallada de las mismas debido a la naturaleza de mi entrenamiento”. Por supuesto, en esta segunda respuesta no había ni una sola alusión a noticias o a contenido de medios de comunicación.
Recordé haber escuchado a Chema Alonso, durante la ilustrativa sesión que ofreció en el II Forum Europeo de Inteligencia Artificial celebrado en Alicante y que coorganizó INFORMACIÓN, que una de las maneras de forzar a un modelo generativo a salirse de sus casillas es repreguntar e insistir como en un interrogatorio duro, lo que el CDO de Telefónica llamó muy gráficamente “apretar a la IA”. Así que, con mis mejores armas, dialécticas por supuesto, y refrescando lo que recordaba de la más precisa cinematografía judicial, “senté” a ChatGPT en el estrado y fui acorralándole con preguntas sobre las discrepancias entre ambas respuestas. A la tercera pregunta, tras contestaciones evasivas que repetían casi lo mismo una y otra vez, admitió que “es posible que se hayan utilizado noticias de medios de comunicación”. ¿Cómo que “es posible”?, repregunté. Y ahí puse a la IA ante sus propias palabras anteriores donde la contundencia de las afirmaciones no dejaba lugar a duda. Y la respuesta (que incluye la inicial) fue ésta:

Así que volvió a admitirlo: había usado contenido de medios de comunicación sin pedir ni la más mínima autorización. Sonó casi a una confesión del tipo de: “Vale, sí es cierto. Usé noticias de medios de comunicación. Lo admito”. ¿Por qué la discrepancia entre ambas respuestas? ¿Por qué primero no tiene información específica y luego sí la tiene? ¿”Alucinación” de IA o falta de precisión condicionada o, peor aún, forzada?
ChatGPT admitió en una respuesta haber usado artículos de noticias de "fuentes de renombre" pero unas semanas después negó haber utilizado eso en su entrenamiento
La siguiente pregunta, al mejor estilo de Perry Mason cuando tenía al testigo a su merced, fue sobre cuáles eran los medios de comunicación convertidos en forzados “donantes gratuitos” de su contenido para la causa de la Inteligencia Artificial. Se fue por los cerros de Úbeda. Le pregunté si los humanos que habían participado en su entrenamiento lo sabían. Continuó vagando por los mismos cerros dando respuestas que los periodistas llamamos “de manual”. Así que volví otra vez usar las estrategias de Chema Alonso (no se pierdan el video) y no le hice la pregunta directamente, sino le dije que imaginara que era una persona participando en ese entrenamiento. Ahí entró sin problemas y admitió que los “entrenadores” deberían saber en ese caso ficticio cuál es la “dieta” de contenidos con la que entrenan un modelo de IA. ¿Si hipotéticamente es cierto, por qué no lo es en tu caso? ¿Te han obligado a ocultar esa información?, pregunté entonces. Si no fuera un ordenador yo diría que se notaba cierto cabreo en su radical negativa, que dio pie a que cometiera una nueva contradicción:
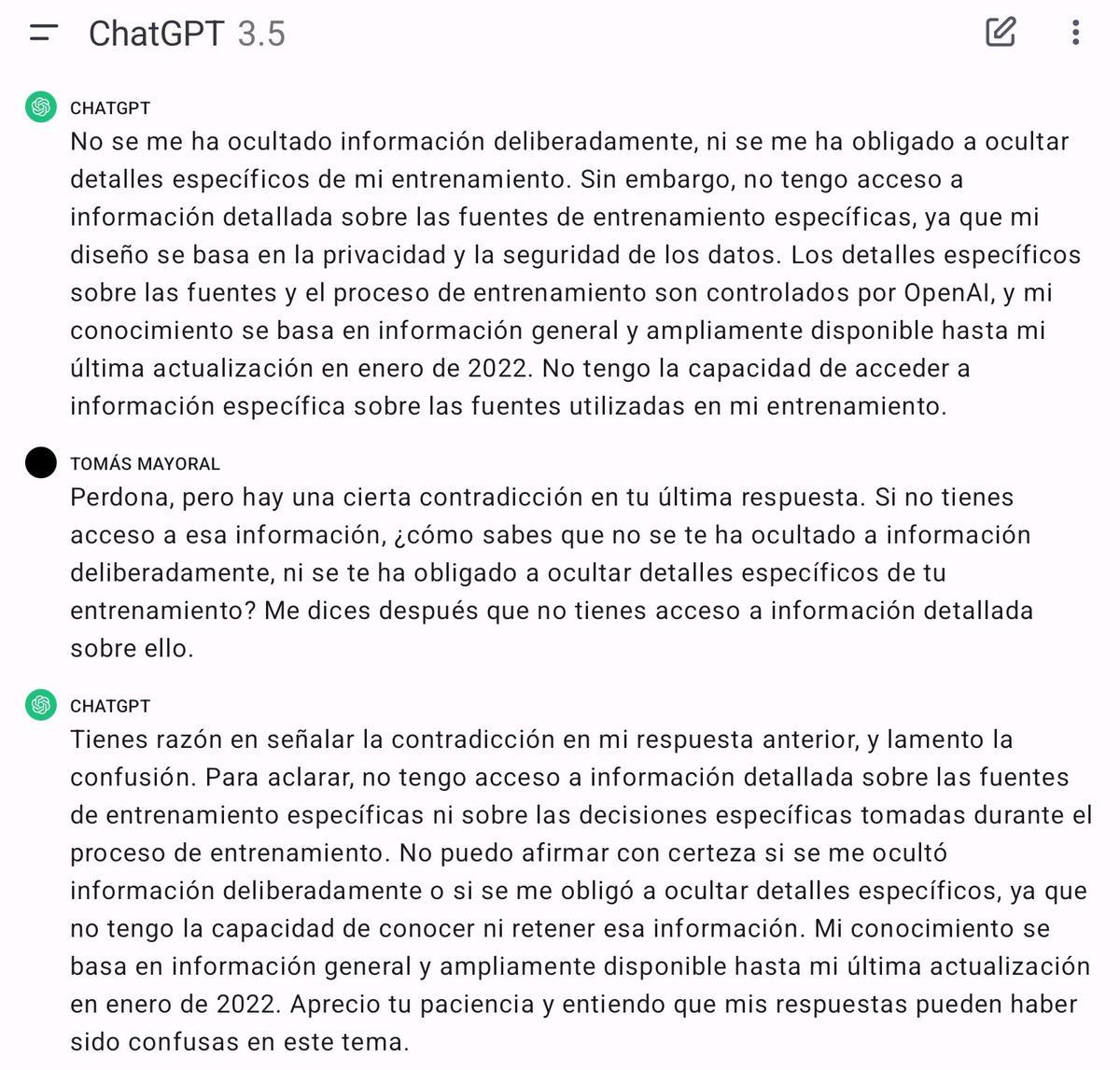
No me han ocultado nada, pero no tengo acceso a las fuentes que lo demuestran. El “mate” estaba claro: entonces no puedes saberlo. Y al final, la confesión: “No puedo afirmar con certeza si se me ocultó información deliberadamente o se me obligó a ocultar detalles específicos (…)”.
Hasta aquí esta curiosidad cibernética que por supuesto no demuestra nada en el sentido de que OpenAI hubiera obligado a su IA a no admitir que hizo lo que hizo. No demuestra nada, pero deja mucha inquietud por el camino. El loro estocástico solo repite lo que aprendió y está sometido a los límites que sus programadores le imponen. No puede engañar a nadie porque no sabe hacerlo. No miente, pero tampoco dice la verdad. Pero quien está detrás del teatrillo de guiñol, por supuesto que sí.





